Use of large-scale optical circuit switches to improve machine learning

While there have been many news stories about machine learning (ML) and artificial intelligence (AI) driven by the recent interest in ChatGPT, a surprising variety of our daily activities have already been touched by ML algorithms. ML is used to determine which movies are recommended to you when watching Netflix or YouTube. The advertisements you see in your feed after logging into Facebook or Instagram are generated by ML recommendation algorithms. When you ask Siri or Alexa for assistance, voice recognition based on ML helps to recognize what you are saying and determines how to respond. Even Duolingo uses AI to personalize users' foreign language lessons based on ML algorithms.
All of this is driving a huge change in the use of information. As stated by Alexis Bjorlin, vice president of engineering infrastructure at Meta, “We’re in the middle of a pivot to the next age of information. AI workloads are growing at a pace of 1,000X every two years.”1 This increase in data workloads has an impact on the hardware requirements as well. Bjorlin continued, “[A]s we look to the future, the generative AI workloads and models are much more complex. They require a much larger scale. Whereas traditional AI workloads may be run on tens or hundreds of GPUs at a time, the generative AI workloads are being run on thousands, if not more."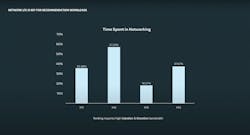
Large language models (LLMs) such as ChatGPT are an example of the expanding sizes of data sets and machine clusters used for ML. ChatGPT-3 was trained using 175 billion parameters while ChatGPT-4 used 576 billion parameters. In terms of the size of the computing cluster, other LLMs such as Gopher, Megatron-Turing NLG, and PaLM used from 2,000 to 6,000 GPUs in their training runs.2
The parameters used for training these algorithms are exchanged after each iteration between these large computer clusters using a collective communications function that shares the results among all the compute nodes. The model is trained until acceptable parameter convergence is achieved, which can take many thousands of iterations. With >100 billion parameters and >1,000 GPUs, worker communication has turned into a significant bottleneck and time spent in networking can exceed the time spent on computation for some ML models, as shown in Figure 1. Since ML training runs can take days to weeks and cost millions to tens of millions of dollars of compute time, finding ways to make the training more efficient is critical.
Increasing ML training efficiency
As has traditionally been the case when bandwidth requirements have increased, the first step is to increase link bandwidth by increasing the baud rate. However, this has become challenging at per-lane rates beyond 100 Gbps for a variety of reasons. The path towards higher-speed links then turns towards an increase in the number of lanes – either in terms of parallel fiber links or with wavelength-division multiplexing. For example, an 800-Gbps link can be achieved by using 8x100G links or 4x200G links. The next step to 1.6-Tbps links will double the number of parallel lanes. Of course, this parallel wavelength or fiber approach increases complexity; more wavelengths mean more lasers and more parallel lanes mean a larger number of fibers to manage between the compute clusters.
While increasing the data exchange rate between GPUs is necessary to improve the speed of ML training runs, there may be other ways to improve the efficiency of ML training. With the large data sets and computer cluster sizes, the computation needs to be split into parts – a method called parallelism. This splitting can be done through either data parallelism or model parallelism. For data parallelism, the large data set is split into smaller units that are then processed by the compute nodes. For model parallelism, different steps of the training algorithm are split on to the different GPUs.
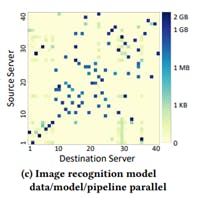
A heat diagram of the data exchange between compute nodes for one specific ML algorithm is shown in Figure 2. This heat map is dependent on the model parallelism and the algorithm being used. Since the data exchange is predictable based on the model parallelism and stable during the training run, optimizing the bandwidth between these high exchange workers can significantly reduce the communication bottleneck and improve the training efficiency.
TopoOpt is the process described above to improve the training efficiency by optimizing the links between compute nodes in ML using model parallelism. A simple example of optimizing the links for a three-node cluster is shown in Figure 3. TopoOpt was developed by Manya Ghobadi’s research team at MIT CSAIL Laboratory in cooperation with Meta and Telescent. By jointly optimizing the network topology and parallelization strategy, TopoOpt achieves a 3X reduction in training times for some deep neural network models. The performance approaches that of a full-bisection bandwidth network at a third of the cost.3
The demonstration of TopoOpt used a robotic patch panel to physically change the fiber links between GPUs, as shown in Figure 4. While the demonstration used a small number of GPUs, the robotic system can have up to 1,008 duplex fiber connections that can be connected and reconfigured in a non-blocking manner. The key element of this system that enables it to scale to high port counts is the patented algorithm that the robot uses to weave the fiber around other fibers to the new location during reconfiguration. The system is always non-blocking no matter what configuration the system is in or how many reconfigurations have already been made. Since it is an all-fiber system, it has excellent optical performance with a typical loss through the system of 0.3 dB. Both single-mode and multimode fibers have been deployed in the system, the latter enabling use with lower-cost, short-reach multimode transmitters. The system is in service in production networks and has over 1 billion port hours in service.
The growing use of optical switches
While introducing optical switches into a computer network may seem unusual, Google has recently published details about their use of a MEMS-based optical circuit switch (OCS) in their data centers.4 In this work the use of a 136-port MEMS OCS to replace the electrical spine switches within the data center Clos-type fabric resulted in a 30% reduction in capital expense and a 40% reduction in power requirements. Another benefit of the OCS architecture is the optical transparency, which enabled the expansion of the data center using different generations of transceivers.
Implementing this technology into the data center network involved developing other technology due to the relatively low port count of the MEMS switch. Due to the small port count of each MEMS switch, Google chose to use bidirectional fiber transmission to effectively double the useful port count of the MEMS system. This approach required nonstandard bidirectional transceiver optics with an optical circulator in each optical pluggable and an improved FEC algorithm due to increased loss and greater return loss in the optical link.

While reconfiguring a 3D torus can be done with an OCS of a limited size since it is only changing connectivity between nearest neighbors, for optimizing large training runs using TopoOpt between GPUs communicating at 800 Gbps using eight-lane parallel optics drives the need for an optical switch that can handle thousands of fibers. This would be extremely challenging for a MEMS-based OCS but the all-fiber robotic patch panel described above can scale to thousands of fibers per system. Since the robot can move any connector, changing from a simplex LC connector to a 16-fiber MTP (multi-fiber termination push-on) connector scales the system by over an order of magnitude with minimal changes in the overall system design or reliability.
While ChatGPT and other uses of machine learning will change the world in ways that we can’t predict today, it is obvious that enabling the use of ML for the range of applications will require improvements in network architectures and the implementation of new ideas such as TopoOpt using OCSs. The transparency of such circuit switches creates significant benefits such as power and capex savings while the all-fiber approach used in TopoOpt enables scaling to the ML cluster sizes used today and in the future.
References
1. “Meta Previews New Data Center Design for an AI-Powered Future,” Data Center Frontier (https://www.datacenterfrontier.com/data-center-design/article/33005296/meta-previews-new-data-center-design-for-an-aipowered-future).
2. “Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance,” Google AI Blog (https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html).
3. W. Wang, et. al., “TOPOOPT: Optimizing the Network Topology for Distributed DNN Training,” USENIX Symposium on Networked Systems Design and Implementation (NSDI '22) April 4-6, 2022 (https://doi.org/10.48550/arXiv.2202.00433).
4. “Jupiter Evolving: Transforming Google's Datacenter Network via Optical Circuit Switches and Software-Defined Networking,” Google Research (https://research.google/pubs/pub51587/).
BOB SHINE is vice president of marketing and product management at Telescent. He brings more than 20 years of experience in technical marketing, product management, sales, and distribution channel management to the role. He has led the market introduction and sales of innovative optical systems and optical monitoring solutions based on new and advanced technologies. Shine was vice president of sales and marketing at Cutera, director of marketing/product management at Daylight Solutions, and head of marketing at several optical communications startups. Bob has a BS, MS (Harvard), and PhD in Applied Physics (Stanford).
About the Author
Bob Shine
vice president of marketing and product management at Telescent
BOB SHINE is vice president of marketing and product management at Telescent. He brings more than 20 years of experience in technical marketing, product management, sales, and distribution channel management to the role. He has led the market introduction and sales of innovative optical systems and optical monitoring solutions based on new and advanced technologies. Shine was vice president of sales and marketing at Cutera, director of marketing/product management at Daylight Solutions, and head of marketing at several optical communications startups. Bob has a BS, MS (Harvard), and PhD in Applied Physics (Stanford).

