Co-processors help meet packet processing challenges
Network processing units (NPUs) provide great value to metro-network equipment architectures by providing a flexible and adaptable processing solution. However, memory-intensive packet searches that serve such purposes as routing, access control, quality of service (QoS), and billing classification can quickly consume both processing power and available bus bandwidth.
Thus, system architects are realizing that additional functionality must be achieved in new and innovative ways: specialized co-processors that accelerate deep packet classification and forwarding in next generation networking equipment. By offloading complex, well-defined, and compute-intensive tasks, specialized network co-processors can benefit NPU-based designs in a manner similar to how graphics processors have benefited microprocessor designs.
Network co-processors can improve the efficiency of NPU-based designs by reducing the bus load and micro-engine utilization, thus freeing NPU cycles for other processing tasks. Performing these searches, often multiple searches in parallel with minimum latency, enables the NPU to implement additional features for future services. Together, the NPU and network co-processors provide a powerful method to futureproof networking equipment designs.
When examined in the context of delivering a feature-rich cost-effective networking system while minimizing development cost and time, the comparative advantages of employing co-processors becomes clear.
A variety of factors make it more difficult for packet processing subsystems to keep up with current demands: Scaling Internet bandwidth, increasing processing workload, and adding new revenue-generating services are just a few. As an increasingly computationally intensive function of packet processing, packet searches play a determining role in a network node’s ability to meet wire speed. Packet searches are ubiquitous in a networking system. At the most fundamental level, one or more databases are searched to determine where to forward packets. But network nodes today must also intelligently decide how and when to forward them. These enhanced processing demands can greatly tax resources. Enabling value-added services such as differentiated subscription levels requires the application of any number of criteria to achieve the result. Validating a packet header alone for security purposes can require as many as eight database searches.
Three NPU budgets must be factored into any network system design: cycle, latency, and external memory bus budgets. The cycle budget, or NPU instruction budget, establishes the number of instructions that can be executed per packet. The latency budget, or cumulative cycles required for all off-micro-engine accesses that can be hidden by multithreading, is determined by the total threads and the interpacket arrival time. The third NPU budget is I/O bandwidth of the external memory bus. More bandwidth is required as functions become more complex, and these buses can become bottlenecks. If the NPU employs standard bus interfaces, more options are available for managing the bottlenecks.
Designers using NPUs must also consider traditional limitations such as pin count and price targets. The number of pins available can limit memory or I/O bandwidth. Price targets dictate many parameters, from die size to chip count to packaging choice.
Addressing more processing capacity with these design constraints yields various options for implementing packet searches. Designers may opt either to implement a highly integrated NPU in which packet search capabilities are embedded in the processor or to employ SRAMs to aid an NPU in searches.
The long tradition of IC design has held fast to the notion that the more integration the better. But to integrate packet processing and searches onto the same chip, functionality must be scaled back since most modern NPUs are pushing practical die-size limits. As a result, single-chip NPUs tend to be customized for a single purpose, thereby limiting the available market. While suitable perhaps for either low-end or lucrative niche markets, the single-chip approach lacks the agility, cost-competitiveness, and processing depth and breadth to be useful for the majority of applications.
Another option is the use of memories, most commonly SRAMs, to assist the processor with packet searches. Uses for the SRAMs vary from system to system and can be employed for Internet protocol version 4 (IPv4) lookups using a trie-based algorithm or ACL searches using heuristic methods. Analysis, however, indicates that SRAM-based designs are adequate for modest standalone performance levels and tables like TCP flow and IPv4 routing lookups but can quickly become unmanageable as search keys widen for Internet protocol version 6 (IPv6) or if more complex matching of ACL tables is needed.* There is also the drawback of high chip count, which can lead to increased board space requirements, board layout complexity, and cost, although the NPU cost may be minimized. Additionally, using SRAMs for packet searches can greatly tax the NPU’s micro-engine utilization as well as its external memory bus bandwidth.
Thus, in the quest to provide network processing subsystems the means to handle high levels of service, data rates, and complex data types, single-chip and SRAM-based approaches fall short of the mark in key respects. Fortunately, the solution can be found in specialized co-processors devised specifically to offload data-intensive searches and classification functions from the NPU. Network search engines (NSEs) hold the key to providing the desired functionality within the cost and performance targets.
NSEs, based on the integration of ternary content addressable memory (TCAM) and high-performance logic, support network processors and ASICs to accelerate packet classification and forwarding in core, metro, and access networks.
To meet the growing demands of service providers, next generation networks must support new applications such as additional services at line rates of 10 Gbits/sec and beyond, efficient support of the larger header sizes used in IPv6, and reduced soft errors for improved data integrity. Fortunately, the newest NSEs have been designed with enhanced features to address these challenges.
The intelligence implemented into gigabit switches and routers requires additional processing and deeper examination of each incoming packet, like forwarding lookups, QoS classification, and policy and admission control. To address these growing requirements, NSEs use such features as simultaneous multi-database lookup (SMDL) to deliver additional search performance. SMDL lookups allow the packet processor to send one key over the external bus and execute multiple lookups in parallel, greatly reducing bus congestion and minimizing latency to enable the addition of value-added services at higher line rates.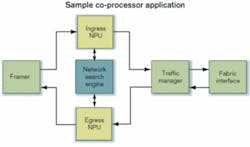
Beyond increased search performance, networking architectures supporting the migration from IPv4 to IPv6 must address the increase of address sizes from 32 to 128 bits, further challenged by IPv6 policy lookups of 296 bits or longer. NSEs offer wide search widths and high performance to optimize IPv6 functionality for accelerated search performance while still retaining backward compatibility with IPv4.
An equally important need exists for a new level of reliability. More stringent service-level agreements (SLAs) will place new demands on networking equipment that translate into new requirements for all critical components in the architecture. Packet processing approaches must specifically address reliability issues such as soft errors to support the five-nines availability that major service providers need to fulfill their service commitments. To address these issues, some NSEs have an error correction code feature to detect in real time otherwise silent errors and correct them without control-plane intervention.
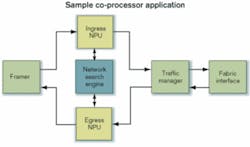
An example co-processor application is illustrated in the Figure. The NSE displaces SRAMs to manage packet-header lookups. The NSE performs all lookup functions (IPv4, IPv6, MPLS, MAC, QoS, ACL) for both ingress and egress paths.
In this example, eliminating most of the costly memory components and reclaiming the associated board space significantly reduce system cost. Full-featured specialized co-processors handle complex lookups internally and return results in a fixed time frame (<100 nsec), improving latency, reducing bus loading, and freeing the NPU headroom for additional features and upgrades. Use of off-the-shelf co-processors also greatly reduces development time since NSEs are supported by comprehensive software development kits for ease in design.
Soaring demand for bandwidth and data cycles has precipitated fundamental changes in network system architecture. The emergence of more specialized and complex system components in the form of network co-processors provides the first viable solution to the problem of managing increasingly complex searches. Co-processors are not a transitional technology but are instead essential components of today’s more successful network processing subsystems.
Dave Carr is chief architect and Audrey Mendoza is product marketing manager at IDT (Santa Clara, CA).
*M. Miller and B. Tezcan, “Design Criteria for Searching Databases,” CommsDesign.com, September 2003.

