Surviving disasters with fast shared mesh protection
Network resilience and disaster recovery are key requirements for today‘s networks as the hyper-globalized economy drives enterprises to adopt distributed IT architectures, such as data center virtualization and cloud-based infrastructure. This interdependence of business processes and the network, combined with an increasing number of natural disasters and man-made fiber cuts, has made it a requirement for the network to recover in milliseconds. At the same time, network operators are moving towards mesh-based transport networks for richer connectivity.
A new class of network resiliency technology, called Shared Mesh Protection, is emerging to take advantage of this architectural shift and deliver more reliable networks at lower cost.
Need for resilience
Network bandwidth is growing at a staggering rate, estimated at 40% growth year over year, driven by business applications such as cloud, mobile, and video technologies. Advances in DWDM now support over 8 Tbps of data per fiber, composed of hundreds of 1- and 10-Gbps circuits. At the same time, the importance of network connectivity has never been greater, with virtually every business process now completely intertwined with network connectivity along with mission critical social, safety, and local government services in most countries.
Both submarine and terrestrial networks are vulnerable to accidental or, in some cases, deliberate outages. Natural disasters seem to be increasing in frequency and intensity, often knocking out multiple fibers simultaneously:
- In 2008, high-profile outages in submarine cables connecting India and the Middle East with Europe happened so frequently that they created widespread speculation that they were the result of terrorist activity.
- In 2009, four simultaneous fiber cuts in San Jose, CA, took out 911 services for an entire day.
- In 2011, a tsunami in Japan took out multiple submarine and terrestrial cables.
- In 2012, Hurricane Sandy took out multiple cables on the Northeastern seaboard of the United States.
In terrestrial systems, “failure by backhoe” remains the number one problem – especially in countries whose infrastructure is developing rapidly and where planning records tend not to be up to date. In fact, in India, some service providers claim that they see as many as 100 fiber cuts per day nationwide.
Around the world, many outages are caused by simple manual errors—such as an engineer unplugging the wrong fiber when making changes. Even in highly developed nations, service providers can face interesting challenges. According to a Level3 blog-post, 28% of their cable-breaks in North America in 2010 were caused by squirrels chewing through the cables. A single outage of just 50 minutes knocks network availability down to four nines, or 99.99%.
Shortcomings of current network resilience strategies
Whatever the reason for network outages, network operators need to plan for failures and implement mechanisms for rapid service recovery. The accepted and entrenched “gold standard” for service recovery to minimize the impact on real-time and business critical applications is 50 ms.
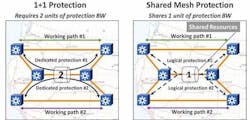
For many years, the most common way to achieve sub-50-ms protection was at the optical layer (typically using SONET, SDH, or DWDM technologies) with a simple hardware switch at the destination node selecting between two identical data streams broadcasted from the source node (a.k.a. “working” and “protect” paths). This mechanism is known as “1+1” protection (see Figure 1) and encompasses the most commonly deployed protection schemes such as Automatic Protection Switching (APS), Subnetwork Connection Protection (SNCP), and Unidirectional Path Switched Ring (UPSR). However, this approach is expensive because it is necessary to reserve an additional 100% of the service bandwidth (or more) for protection, and it only protects against failures in one path.
As we have seen, single-failure protection is no longer sufficient. Extending 1+1 to provide multi-failure resilience (e.g., 1:N) requires using three times (or more) network bandwidth than the data being transmitted. Such a scheme is simply too costly in the face of rising traffic and the cost pressures faced by network operators.
In the early 2000s, software-driven service restoration in optical networks (primarily based on Generalized MPLS) was introduced as these networks moved away from star and ring topologies to more flexible and efficient mesh topologies that could provide multiple backup routes. These recovery schemes attempt to restore services affected by a failure by dynamically rerouting them over unused network bandwidth. These mechanisms are very efficient in terms of bandwidth utilization because all unused network bandwidth is treated as a pool of shared protection resources. [3], [4]
The shortcoming of these software-driven approaches is that recovery time is typically fairly long (hundreds of milliseconds, seconds, or even minutes) and is highly variable depending on the size and complexity of the network, the number of services affected by a failure, and the number of hops needed for recovery. This delay is caused by the many software-based functions that need to be completed before the service is restored: calculating alternative paths, signaling the new connections across the network, and implementing connections in the nodes. In addition, there is no mechanism to automatically maintain adequate “spare” bandwidth in the network to guarantee service recovery.
Similarly, IP traffic is often protected using MPLS Fast Re-Route (FRR) and/or IGP re-convergence, establishing IP links connected over static WDM fiber routes. FRR can provide <50-ms localized recovery for failures. But it requires the network to add both extra IP and optical network bandwidth, is operationally complex, and leads to a lot of network-wide reconvergence updates in router networks when failures occur.
Fast Shared Mesh Protection
Taking the best from each of the mechanisms above, the ideal resilience technology should offer four fundamental capabilities:
These four goals can be achieved by applying the emerging Shared Mesh Protection (SMP) architecture to optical networks coupled with hardware-based control plane acceleration to create “Fast SMP.” The SMP architecture provides software intelligence for service rerouting while eliminating most of the real-time route recalculations and network signaling.
The SMP architecture pre-defines and pre-signals one or more logical protection paths for a service in a mesh network. However, these logical protection paths are not pre-provisioned, so no network resource is dedicated to any specific service. Therefore, many services can have logical protection paths that share the same resources (wavelengths, time slots) in a pool of reserved shared protection bandwidth (as seen on the right-hand side of Figure 1). The working paths of the services that share resources should be disjointed, such that only one of their protection paths will use the resource(s) for a specific failure scenario.
The first step in an implementation of SMP is determination of the logical protection paths required in a network. An integrated network planning and service provisioning application determines the logical protection paths required per service to meet the defined service-level agreement (SLA):
- protection against all single failures
- protection for a subset of failures
- protection against multiple failures.
Additionally, the planning algorithms ensure that for each failure scenario, two or more logical protection paths do not use same shared resource.
The process above determines the currently reserved protection resources, and then calculates the additional shared protection resources that need to be reserved. For example, for protecting a 10GbE service, if a link in the SMP path already has 10 Gbps or more protection bandwidth reserved, no additional shared protection bandwidth is needed, assuming there are no common failure scenarios. However, if the link only has 2.5 Gbps reserved already, another 7.5 Gbps of shared protection bandwidth needs to be reserved.
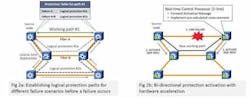
After planning, each logical protection path is signaled, using GMPLS, to all the network elements participating in the logical path. Based on this signaling, each node preconfigures, yet does not implement, the required cross-connects to set up the protection path (Figure 2a). This streamlines the real-time steps needed for activation of the protection path.
Hardware acceleration of path activation
The use of predefined and pre-signaled logical protection paths architecturally eliminates several steps that have made existing dynamic reroute implementations slow and variable in performance; the route computation is already completed and the cross-connects in the node are already calculated. However, to guarantee <50-ms protection performance for longer paths, e.g., 10 hops and for hundreds to thousands of services affected by a failure, both the activation messages must be processed and forwarded, and the protection path cross-connects must be implemented within a maximum time of 2 to 3 ms per node.
One or more real-time hardware control processors are dedicated to achieve this fast performance. The use of this dedicated hardware in each line module and switch module of a node removes the performance constraints found in software-based methods.
Another performance enhancement is the use of bi-directional path activation. Upon failure detection, nodes at both ends of the service start the activation of the protection path for faster convergence.
At each node receiving the activation message, the real-time control processor forwards an activation message to the next node in the logical protection path and implements the pre-calculated cross-connects to establish the protection path in maximum time of 2-3 ms (as shown in Figure 2b).
Priority-based resiliency
In real-world networks, not all services have the same uptime requirements. For example, business-critical traffic needs to be recovered within milliseconds, while best-effort Internet traffic can withstand longer delays. SMP architecture includes multiple levels of service priority to enable prioritized service recovery to match network resource use with business priorities or SLAs while keeping overall network cost low.
With service priority and pre-emption, resources reserved for protection of high-priority services, when not used, are made available for lower-priority services; this reduces network capex. Figure 3 explains those scenarios where the SMP path of a high-priority service shares resources with the working path of a pre-emptible service (Figure 3a) or shares resources with a SMP path of a low-priority service (Figure 3b).
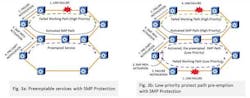
Figure 3 also shows the sequence of the events that happen during activation of SMP paths and pre-emption of low-priority services. The pre-emption notifications (Events #4 in Figure 3a and #7 in Figure 3b) are the only additional events required for pre-emption compared to the case where pre-emption is not required. Hardware-assisted processing of SMP path activation messages has the same behavior for SMP path activation with or without pre-emption; hence, service recovery time is unaffected due to pre-emption. Pre-empted low-priority services can use an alternative (higher cost) path for recovery.
In conclusion, hardware-accelerated fast SMP is much more efficient and robust than today‘s optical networks or MPLS FRR-protected IP networks. These new capabilities make it possible, from both a technological and commercial perspective, to cost-effectively increase the resiliency of a network to recover from everyday faults and large-scale disasters.
RESOURCES
[1] ITU-T G.808.3., “Generic protection switching - Shared Mesh Protection,” approved October 2012.
[2] Draft Recommendation ITU-T G.ODUSMP, “OTN protection switching - Shared Mesh Protection.”
[3] Zhang, et al., “Shared Mesh Restoration for OTN/WDM Networks Using CDC-ROADMs,” in Proc. ECOC 2012.
[4] D.R.Jeske, et al., “Restoration Strategies in Mesh Optical Networks: Cost vs. Service Availability,” in Proc. PRDC 06.
Soumya Roy is senior manager, product marketing at Infinera. He is responsible for tactical and strategic delivery of competitive content, analysis, and network modeling. He is involved in positioning and marketing of Infinera’s products and solutions to customers globally. Soumya will participate in "The Road to 1 Tbps" panel at the Lightwave Optical Innovation Summit on July 16.
Wayne Wauford is director, technical marketing at Infinera. He is responsible for market development and product marketing activities. Prior to Infinera, Wauford held executive engineering and marketing positions at Ciena, Cisco, Bell Communications Research, and Pacific Bell.

