Accelerating the 400 Gigabit Ethernet Rollout with QSFP-DD
400 Gigabit Ethernet (GbE) is finally ready for prime time. Vendors are releasing hardware, and network operators are rapidly transitioning from evaluation to deployment.
Historically, high-speed Ethernet network interfaces were initially driven by service provider requirements for density and spectral efficiency. The optical modules were initially quite large – usually one per card. Over several generations, every speed converged to one of two module form factors: SFP and QSFP. These milestones led to lower cost and power as volume rose dramatically.
According to LightCounting’s projections, the five-year ramp of 400GbE is projected to be 20 times faster than 100GbE even before copper and active optical cables are included (Figure 1). This opportunity has led to an unprecedented industry investment by both established players and startups.
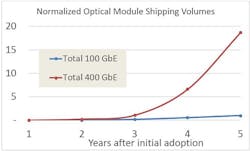
Figure 1. Comparing first five years of 100GbE vs 400GbE. (LightCounting projection for 400GbE module volume.)
400GbE on the fast track
10GbE took 10 years to evolve from XENPAK to SFP+. 100GbE was deployed with CFP, CPAK, and CFP2 before reaching QSFP28 in 5 years. 100GbE also suffered from a misstep with CFP4, which provided a critical lesson that optics must be in sync with other goals of the platform, network, and business. If not, time and capital are wasted. CFP4’s size was appealing, but it broke backward compatibility and didn’t align with the requirements to achieve all goals in the three areas just mentioned.
Achieving high volume and low cost for 400GbE is critical to network operators, silicon manufacturers, optics vendors, router and switch vendors, and many other members of the optics ecosystem. A notable success of the 400GbE rollout is the convergence on the rate and a set of PMDs by the IEEE, OIF, and multi-source agreement (MSA) members. This should not be taken for granted, as other speeds were proposed. In addition, one of the crowning achievements of the 400GbE rollout is that it will be the first speed to support all reaches and media with small modules (32 or more per RU) in its first implementation.
Regrettably, the industry initially has two pluggable module formats, causing duplication of development and manufacturing. This duplication risks reducing the market’s ability to scale around a common solution.
The drawbacks of duplicate transceiver formats
Among the key factors in the success of the 400GbE rollout will be cost, investment protection, and supply chain. When cost is critical, it’s important not to overbuild capabilities. The initial 100GbE standard was 10 km over single-mode fiber. Later, shorter reaches were developed to optimize for reduced power and cost. 400GbE will benefit from having a full range available much sooner and in small form factors – initially from 1 m to 10 km in 2019 and then 100 km in 2020.
Another driver of cost is reaching economies of scale. Unfortunately, the duplication of module formats prevents the market from taking full advantage of the other aspects of alignment. Streamlining manufacturing is crucial to unlocking economies of scale. Volume drives yield and thus cost. A common production line is therefore key, and a vast ecosystem with dozens of companies benefits from standardization. This ecosystem includes developers of manufacturing equipment, test equipment, software design tools, connectors and cages, thermal solutions, compliance and qualification equipment, and many more. Reaching commonality quickly is crucial given the anticipated early and rapid growth of 400GbE.
Why backward compatibility is essential
Over the past decade, the ratio of cost between the host platforms and the optics has shifted substantially towards the optics. This trend will only increase with 400GbE. Generational compatibility will help offset the impact of this trend. Over 24 million QSFP modules representing an over $8 billion investment will be deployed by the end of 2019. Even as 400GbE rolls out, QSFP 100GbE will continue strong growth driven by the emergence of 100GbE servers and as enterprises and service providers increase bandwidth throughout the network.
It is not sufficient to add greenfield equipment and run the same network faster. There are multiple aspects of backward compatibility that must be considered, including reusing existing modules as well as the continued investment in 100GbE. This is only possible when the new ports support existing modules.
Second, the cost, power, and footprint benefits of deploying the latest routers and switches occurs even before the capabilities of 400GbE are required. This enables operators to prepare their networks for future growth and benefit from new hardware without committing to the first-generation 400GbE optics immediately.
Finally, investment in installed routers and switches must be protected. This requires compatibility with the cooling architecture (e.g., top to bottom or side to side). QSFP-DD solves this problem by separating the module and the heat sink, which enables the host system to be customized for its needs.
Backward compatibility should be maintained whenever possible. Extending compatibility across three or even four generations is as technically demanding as it is valuable. The decision to balance investment protection and optimization for new requirements is never straightforward. The debate in 2017 and 2018 was whether this form factor transition would be required at 400GbE, 800GbE, or even higher speeds.
It is generally agreed that a form factor transition should occur when absolutely required due to technical issues or cost. Achieving investment protection, high density, and a full set of capabilities required taking risks, but they have now been fully resolved in QSFP-DD, thus enabling the industry to move forward with improved economy of scale.
QSFP-DD challenges – and solutions
Achieving backward compatibility with QSFP-DD required solving a wide range of challenges, including component size and layout, module and system cooling, and electrical connectors supporting four and eight channels using 56G SerDes. These factors are tightly coupled and needed to be considered in conjunction with other system components such as high-power ASICs. Naturally, these mechanical challenges are easier in a greenfield module that breaks compatibility with earlier generations.
One of the most visible technical challenges is thermal dissipation. The initial 400GbE PMDs were anticipated to require 12 W. Given that QSFP28 only supports approximately 4 W, it is understandable how some would consider this a step too far. The success in reaching the initial goals led to even more ambitious plans. The 400ZR/ZR+ coherent modules planned for 2020 may require as much as 20 W. Continued innovation, including system and cage design, has shown that this is possible, and standards groups will soon ratify these solutions for QSFP-DD. The last step to support 20 W has been accomplished by adding a heat sink integrated into the front of the module as shown in Figure 2.
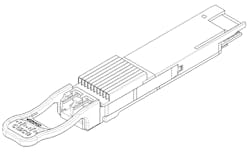
Figure 2. QSFP-DD module showing integrated heatsink on nose to enable 20 W system cooling for ZR+.
Another thermal consideration is that optics modules cannot be viewed as a closed system; they must work within the overall design of the router, switch, or server. A valuable characteristic of QSFP modules over OSFP is that their smaller footprint allows for greater air intake. This factor benefits the rest of the system, which can be clearly seen in platforms offering both options.
There are many other areas where the work to achieve investment protection in QSFP-DD required a massive, industry-wide collaborative effort. Significant technical advances, many considered impossible at first, have been made at each step along the journey from 40G to 400G. Work has already begun to address these challenges for future Ethernet speeds. Repeating the prima facie argument that QSFP has reached its limits should be viewed with skepticism.
Managing supply chains has become a key differentiator for successful hardware vendors and network operators. With massively scalable data centers deploying in such large volumes, diversity of suppliers is critical, and each of these suppliers may unfortunately have to split their supply chain management if both module formats persist. Similarly, supporting multiple modules has an impact on sparing – an important issue if both modules are required by service providers with equipment in many smaller sites.
The best market option must be available in volume at an acceptable cost. Once convergence on module format is reached, the 400GbE rollout will benefit from optimization by all contributors and multiple competitive sources along the supply chain. We cannot repeat the experience of CFP4 merely to pursue a perceived and unfounded short-term reduction in risk.
Summary
400GbE rollouts are beginning in 2019 and will accelerate rapidly. The debate on optics module format is largely over – although the focus is shifting to future speeds as system vendors have either settled on QSFP-DD or chosen to provide duplicate products. Long term, 400GbE will be deployed primarily with QSFP-DD, so the merits of an intermediate step without a compelling case beyond some future benefit is questionable.
As the industry continues to converge on QSFP-DD, the economies of scale will manifest and allow 400GbE to reach its full potential.
Lane Wigley is a technical marketing engineer at Cisco . He is a 25-year veteran in the networking industry and focuses on Cisco’s high-end routing and optics portfolios.
About the Author
Lane Wigley
Technical Marketing Engineer, Cisco
Lane Wigley is a technical marketing engineer at Cisco. He is a 25-year veteran in the networking industry and focuses on Cisco’s high-end routing and optics portfolios.
Voices of the Industry

