Total approach to optical-network testing
Finding the right optical-network performance-management tools to meet customer demands.
BY JAAN LEEMET and GIOVANNI FORTE, Avantas Networks
End-to-end service is only as good as its weakest link-just ask any service provider. In today's increasingly competitive, technologically complex optical-network environment, service providers must detect, prevent, and correct network service degradation inexpensively, efficiently, and quickly. That's hard to do with so many network service protocols and interfaces, coupled with the ongoing drive to support higher bandwidth links over emerging service platforms.
As higher bandwidth services from the core to the periphery of the network accelerate, service providers must rely on service assurance technologies to ensure optimal network performance. Quality-of-service (QoS) assurance is no longer a value-added luxury. It is a necessity-and without it, no carrier survives. The most expedient, cost-effective way to manage increasing bandwidth at the edges of an optical network is to deploy remote optical-network test equipment and optical monitoring probes that integrate into existing network-management and service provider operation support systems (OSS). This total approach to managing the entire optical performance network ensures providers will meet and surpass customer expectations-today and tomorrow.
In this post-deregulation environment, excellent customer service is tantamount to survival. Quality and availability of service can make or break customer relationships, and carriers have responded with competitive pricing and improved service turnaround. Network operations control (NOC) centers serve to fine-tune operations so providers can offer innovative new service technologies with service guarantees.
Today's central offices (COs) are filled with numerous technologies provided by a multitude of vendors, each with its own management system. This poses an ongoing challenge to service providers-how to offer and monitor the same service guarantee across multiple networking technologies. Among the formidable tasks providers face are gathering and interpreting performance-monitoring data coming from numerous technologies and keeping up with various management protocols-especially difficult considering the breakneck pace at which system software is revised. A technology- and vendor-neutral service assurance platform is essential to help providers accomplish these goals.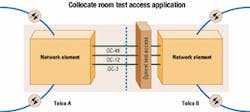
Increased competition prompted carriers to create the service-level agreement (SLA), a very effective service differentiator. Service guarantees at a variety of levels entice potential customers, and these premium services are possible only through advanced management systems that correlate data from the various optical-network elements and test-and-monitoring devices installed in the field. With the right tools, operators can target and resolve problems quickly and efficiently from their NOC centers.
A variety of monitoring and early warning indicator devices assure quality and availability. NOC personnel use surveillance and trending tools to characterize network activity and detect any sign of possible degradation before it turns into an outage. To provide quality assurance and availability, each end-to-end service must be monitored against a given set of criteria. There are standards for availability; the most commonly used is the International Telecommunications Union (ITU) G.821/826, now the G.828/G.829.
First, outages must be measured and detected by providing bit-error-rate measurements and errored seconds/severely errored seconds/unavailable seconds/available seconds times from the equipment. Monitoring software will generally provide end-to-end numbers based on the worst figures of the equipment in the end-to-end link.
However, the relationships and interdependencies of this intermediary equipment are not always obvious. In some cases, if a link is lost for a mere second, resynchronization may be required by equipment further down the line. The one-second outage may become a 30-second loss of service for the customer. So it's essential to provide measurements that reflect the customer's actual condition.
To make matters worse, not all optical-network equipment vendors provide numbers in the same formats or use the same criteria to determine availability. Equipment may not consider re-synching times, may lose data over a reboot, or simply may not provide this kind of data. Forward error correction (FEC) schemes can improve bit-error rates to keep optical equipment in an available state, but there are limits on what and how much can be corrected. The ability to measure how hard FEC schemes are working at any time is crucial because it allows setting thresholds to create warnings of an impending or possible outage to come.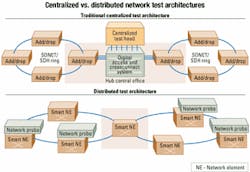
New data-centric, packet-based services also pave the way for a whole new set of parameters in defining SLAs. Evolving sets of recommendations and requests for comment from the Internet Engineering Task Force (IETF) and other work groups define parameters, such as sustainable throughput, maximum burst size, end-to-end latency, and packet loss rate. These parameters define performance availability as "a measure of the ability of a network to provide packet communication with sustained and reliable performance." These parameters have become especially critical with the emergence of such real-time, performance-sensitive services as voice- and video-over-IP.
As the optical network expands, so does remote testing. Carriers and service providers install test heads in their networks to provide testing capabilities or monitoring features not offered by their traffic-carrying optical equipment. These provide a vendor-neutral, reliable set of performance data used for non-intrusive testing to better characterize faults when degradation is detected. They also can be used for intrusive testing by generating test patterns carried across the network, stressing and verifying links upon turn-up.
Traditionally, these test heads have been centralized in the CO. That is due, in part, to the high cost and complexity of testing equipment, but moreover it's due to the lack of test access other than at the core of the network, where digital crossconnect systems are used. As more digital crossconnect functionality is integrated, test access becomes more geographically widespread.
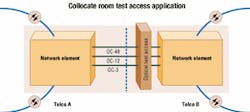
Instead of being constrained at the core of the optical network, test access now can be used throughout the periphery of the network at remote points of presence, at sensitive customer premise equipment locations, or in collocation sites, where optical handoffs are often the subject of disputes and finger-pointing among neighboring carriers (see Figure 1).
Deregulation prompted more handoff points and more players, each wanting to measure performance in its part of the optical network as well as the QoS it received from leased facilities. As the optical network evolves, the traditional centralized approach to remote testing falls short in its ability to isolate faults and diagnose trouble accurately. When testing tools are available only at a central site, the root cause of trouble in a network may not be obvious to isolate.
Sometimes the traffic under test must be backhauled through the network, but that uses precious bandwidth. Further more, the view of the customer at the problem site and what the test head sees at the centralized location may not be the same. Also, there may be compensations throughout the backhaul traffic path that correct errors along the way, thus masking a problem. A customer service may span across optical, wireless, and electrical systems along its path and go through a number of intermediate protocol conversions. In a troubleshooting scenario, the service provider must ensure each of these sublinks is performing optimally-a complex task if there's only one centralized test device.
Scalability and network planning are also factors. As the optical network grows, it is easier to scale a distributed optical test system by adding units as they're needed and deemed appropriate. By contrast, traditional centralized test heads are much more difficult to scale. Distributed optical test systems also allow redeploying and reusing test devices as the network topology evolves, which saves money.
In an effort to provide end-to-end service to users, many large carriers have developed their own in-house systems to monitor and detect faults, collect performance, and perform service activation, provisioning, and customer care. But inherent obstacles make these tasks difficult to achieve. For example, to bring up a service or diagnose a fault, each multivendor hop in the data path must be queried and configured to provide its monitoring part in the end-to-end path. However, the frequency of software or equipment up grades on very different products, along with the resulting rework to performance data-gathering systems, and the disparity between which data is available from each vendor, can make for frustrating, lengthy, and inaccurate analysis.
While evolving standards are sometimes supported, in implementing them, vendors in various states of completion often push them their own way-sometimes in an attempt to leave the competition that much further behind while they're busy reworking their own implementations. Integrators at NOC centers must be ready to deal with transaction language 1 (TL-1) interfaces, common object request broker architecture (CORBA), proprietary, simple-network management protocol (SNMP) with standard and enterprise management information bases, or often a mix. As the equipment evolves, each new release may provide additional commands, object identifiers, or attributes, making the OSS integration efforts seem never complete.
Remote test heads have been one of the key building blocks in SLA-conscious network deployments. Having test heads available directly from the NOC solves time-consuming problems, such as obtaining site access rights and finding technicians with the right expertise-and getting them to the site.
With today's multiprotocol/multi-interface sites, finding an individual with the expertise needed in close proximity to each site when problems arise-armed with the appropriate test equipment-is not only costly, but next to impossible. With the aid of remote testing capabilities in the NOC, professionals capable of diagnosing network problems can be situated at regional or centralized sites where they can apply their expertise across the network more efficiently.
The drive for efficiency and accuracy in testing has also shaped the test head arena. Now remote test and monitoring equipment can monitor and diagnose a wide variety of interfaces and protocols in the same box. That saves real estate, costs less, and makes it possible to situate test equipment where it is needed most-close to the all-important customer. As with fiber networks, in which fiber rings expand out toward small businesses and homes, the ability to monitor and test links is expanding with the network (see Figure 2).
These two trends are prompting wider distribution of remote test and monitoring equipment. Carriers want to view what is happening at the edge of the network to monitor and capture problems as close to where they occur as possible. Next-generation universal network probes give them the means to do this. They are cost-effective, scale well, and cover a variety of interfaces [from DS-0 (64 kbits/sec) to OC-192 (10 Gbits/sec) and DWDM] within one space-saving box-an important factor in collocation applications. Some vendors have both data communications and telecommunications test capabilities in a single device.
Sometimes integrating remote test equipment with traffic-carrying optical-network elements can be difficult. Next-generation network elements (NEs) and digital access and crossconnect system equipment provide test access and monitoring ports that can be crossconnected to a test device. Again, in a multivendor (or even multiversion) environment, each optical NE has its own interface, security constraints, and protocols. In some cases, a simple optical tap can be used for extracting performance data or to do non-intrusive testing. But even with a 5% or 10% tap, the user may eat into a predetermined optical power budget. In general, one or more ports must be used from the NE for connection to a remote test device.
When executing a test via a particular interface on the NE, the test device vendor can provide a path to the test set through a crossconnection to the dedicated test port (or ports). Some NEs may provide a monitoring port crossconnect that duplicates data so that it won't break the live traffic. To facilitate these interfaces, dedicated test access servers maintain relationships with the test equipment, connected switches, and northbound systems. Once these relationships are established, access rights, queuing of requests, and error handling with these devices must be provided.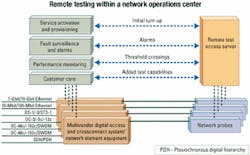
In the past, interfaces to popular equipment would be provided by a test set vendor as part of its test access server or testing element-management system (EMS). But with the aggressive speed at which new devices appear and existing devices evolve, this strategy becomes less and less feasible. As carriers demand more interoperability in systems, open system architectures are a must in order to provide hooks on which to add devices of choice to management systems.
Because test set vendors and system integrators cannot keep up with the interface requirements, hooks have become essential. Hooks can call external applications or scripts from within the testing EMS, which enables test access to be added, modified, or customized to a customer's specific requirements without affecting the core of the test-management system. This flexibility allows carriers and NOC operators to maximize their tools by automating common operations and streamlining operations.
For the NOC operator, having test equipment distributed in the network is like having dedicated technicians at critical sites on call 24 hours a day, seven days a week. It gives NOC personnel automatic access to tools they need by pre-installing them at key locations, thus reducing the number of skilled diagnosticians needed at every site.
Further integration within the OSS systems provides even greater advantage. By integrating remote test devices into a variety of NOC applications, a problem can be pinpointed and solved faster.
Normally, a fault-management system receives messages from an NE's EMS and generates a trouble ticket as a service request to a technician. With today's advances in network-management integration, the fault system can (and should) automatically generate a preliminary test report by using a remote test head located close to the problem area. These test results are attached to a trouble ticket to aid the technician if a dispatch is still required. Because timing is often critical, automated testing saves crucial moments by better characterizing intermittent problems, thus eliminating the time it would take for a technician to arrive onsite.
Performance-management systems also benefit from the use of distributed remote test systems. Rather than simply creating a threshold crossing alert, a performance system may decide to launch a series of tests using a remote test head to gather more data on a problem. It may dynamically reconfigure thresholds or polling intervals to gain more insight into potential problems. Service activation systems often provide interfaces to provision multiple EMS systems over an end-to-end link.
A logical step in this process is to automatically start a turn-up test on the new circuit to validate and benchmark a new customer line. These baseline test results are stored and compared against periodic follow-up tests to monitor potential degradation of the circuit. Again, much of this can, and should, be automated (see Figure 3). Finally, with access to remote test heads, customer care personnel can provide instant feedback to customers while they're on the phone, rather than having to make follow-up calls that are costly and frustrating to customers.
Today's cost-effective and versatile optical-network performance-management equipment provides service guarantees and added value to an NOC's day-to-day operations. These remote testing devices are no longer luxuries in central sites, but have become a necessity throughout the network. Next-generation universal probes provide vendor-neutral, multi-interface/multiprotocol test and monitoring capabilities, use less real estate, integrate seamlessly with OSS systems, scale better, and provide a more cost-effective solution.
This new network surveillance gets the most of carriers' and providers' management systems by adding automated testing. As strides in integration continue, the real winner is the end customer who enjoys better service.
Jaan Leemet is director of optical-network solutions and Giovanni Forte is vice president of product management at Avantas Networks (Montreal). They can be reached at [email protected] and [email protected], respectively.

