The "old reliable" rings
With data-centric traffic becoming predominant in the MAN, Resilient Packet Ring technology bolsters network reliability and availability.
John Hawkins, Gady Rosenfeld, and Kanaiya Vasani
Resilient Packet Ring Alliance
The traditional metropolitan area network (MAN) is the focus of significant attention by today's telecommunications providers and consumers. It has gathered attention for good reason, as it has not kept pace with bandwidth increases in LANs and WANs, and hence has earned the reputation of being the bottleneck in today's data-centric network. A myriad of technologies have been fielded to address this bottleneck, and while the jury might still be out on the long-term winner, one thing is clear: providers and end-users will not settle for solutions that cut corners on reliability and robustness.
The roots of the current MAN technology are easily traced to the voice network. The venerable T1 circuit (still the mainstay of today's carrier-based MAN offering) was developed as a metro technology, whose capacity and distance specs were targeted at large North American metropolitan areas. The T1 was not only a convenient way of multiplexing and transporting digitized voice calls; it was also very reliable thanks to redundancies built into the systems deployed in most carrier applications.
This channel-based protection was extended to the fiber-based core of the network via SONET/SDH -- another legendary technology, known for its resilience and carrier-class features. SONET/SDH offers more than just reliability, however, as a host of performance management features, plenty of multiplexing levels, and most importantly, vendor interoperability have made it the most successful optical transport technology in the world.
It was not, however, devised with bursty data traffic in mind. While data networks have been mapped onto SONET/SDH (creating so-called overlay networks), these suffer from several shortcomings that lead to the aforementioned bottleneck. For one thing, time-division multiplexed (TDM) circuits are of fixed size and are not multiplexed together in a way that is efficient for data carriage. This sizing mismatch results in the so-called stranded bandwidth in today's networks, whereby available capacity goes unused. It also means capacity is hard to reallocate based on real-time bandwidth usage.
Changes and their driving forces
While adequate for the data needs of the past, these overlay networks do not offer the scalability nor achieve the cost efficiencies required to meet the market demands of the growing data-centric enterprise. ATM and frame relay services become cost-prohibitive for most customers at rates of over 45 Mbits/sec. Symmetric DSL services, although priced lower, do not scale beyond 1.5 Mbits/sec. With growing customer demand for affordable network access at speeds of 10 Mbits/sec, 100 Mbits/sec, and more, there is a clear need for a new class of data service that is more scalable and cost-effective.
Ethernet-based services are expected to fill this void. It is widely believed that Ethernet services will be the successor to ATM and frame relay services in MANs.
As a service interface, Ethernet has a number of benefits. Subscribers do not have to deal with technologies other than the familiar Ethernet (95% of all enterprise LANs are Ethernet-based). It is also a more cost-effective solution because it eliminates the need for expensive V.35 interfaces in access routers and demarcation equipment such as T1, frame relay, and ATM require. The customer's access router is connected directly to the network using one of its native Ethernet ports.
Ethernet also provides a highly scalable physical interface. A service provider can drop a Fast Ethernet (100-Mbit/sec) or Gigabit Ethernet (1-Gbit/sec) port to a subscriber once and upgrade many times, without additional truck rolls beyond the initial installation. Bandwidth and other service changes can be administered remotely, simplifying and facilitating service provisioning.
Initial Ethernet service deployment, however, hasn't been as smooth as one would have hoped. One of the major problems that has hampered the spread of Ethernet in the MAN is the baggage associated with its non-carrier origins. Issues such as support for customer-specific service level agreements (SLAs), weighted allocation of network resources to end-users, and 99.999% network availability did not exist in nor were required by enterprise LAN environments.
For Ethernet services to be successful, they must offer enterprise customers the same reliability features that are taken for granted with their legacy network services and more. Carriers need to offer SLAs guaranteeing very high availability and up time, which are backed by financial penalties for non-performance. In time, as the network continues to become a mission-critical component of corporate infrastructure, network reliability and service availability will only become more important.
Enter RPR
Resilient Packet Ring (RPR) is an emerging network architecture and technology designed to meet the requirements of a packet-based MAN. An RPR network is a ring-based architecture that consists of packet-switching nodes interconnected by dual counter-rotating fiber pairs.
The Institute of Electrical and Electronics Engineers (IEEE) 802.17 Resilient Packet Ring Working Group is developing standards in this area. The working group is establishing standards for a media access control (MAC) layer for data transport on a metropolitan-area ring network.
Transporting packets across a shared medium is a problem typically handled at the MAC layer of a protocol stack (known as Layer 2 of the well-known OSI stack). By controlling access to the medium (in this case the fiber ring) and arbitrating requests for its use, the MAC layer is able to guarantee service quality (i.e., delay and jitter) and bandwidth management.
One key component of the RPR MAC is its ability to provide SONET-like resilience while remaining a packet-based technology. The RPR MAC includes protection schemes that react to fiber cuts, node failures, and other outages on the ring and reroute traffic around points of failure. And it accomplishes this within 50 msec, the golden standard set by SONET/SDH. But unlike SONET-based protection schemes, the RPR protection mechanism does not reserve one half of the ring to be dedicated for protection traffic. Both rings carry traffic during normal operation.
Resilience in RPR
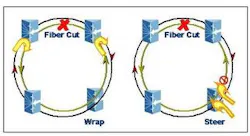
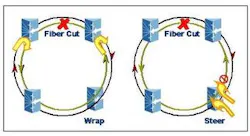
To accommodate metro applications including pure data applications as well as multi-service applications, the RPR MAC supports two protection mechanisms: wrapping and steering. Each mechanism has its advantages, and support for both ensures that service providers can optimize their networks according to the particulars of the application.
In wrap protection, if an equipment or fiber facility failure is detected on one ring, traffic going to and from the failure is wrapped (or looped) back in the opposite direction using the other ring. Wrapping takes place on the stations adjacent to the failure, under the control of the protection switch protocol controlled by the MAC. The wrap essentially re-routes the traffic away from the failure as shown in Figure 1.
For steer protection, a station will not wrap a failed ring segment when a failure is detected. Instead, all stations are constantly kept aware of the status of each link and in the event of a failure will "steer" traffic away from the failure. Source stations thus retain the responsibility of directing traffic onto the appropriate ring, the one that avoids the failure. This scenario is also shown in Figure 1.
Steering is the default protection mechanism in the current proposed RPR standard. This means that when an RPR ring contains stations that can both wrap and steer, they will default to steer protection to ensure interoperability.
MPLS-resiliency solutions
RPR provides fine grain, dynamic, and bandwidth-efficient protection for the metro ring. This allows carriers to efficiently use their metro infrastructures. As we mentioned, in the core of the network, connection-oriented protection methods are currently in use, which include SONET/SDH circuit-based protection as well as wavelength protection provided by DWDM equipment. We have established that RPR provides resiliency on an RPR-based ring. However, resiliency should also be available on a per-service level and across various transmission technologies, network topologies, and policies. Specifically, a service between two RPR-based networks could be carried over a different transport network, or different services could be defined by different levels of resiliency. This requires a unifying control plane that can guarantee high service availability.
MPLS has been proposed as a unifying technology that can bridge between various topologies and transport methods to provide end-to-end protection in addition to its well-known traffic engineering capabilities.
The IETF is engaged in defining MPLS-based mechanisms for recovery of packet-centric networks. Two current mechanisms for recovery are (1) detour to a pre-established label-switched path (LSP), and (2) an established-on-demand path. The first mechanism shows great promise in providing relatively quick recovery times. Regardless of the method adopted, it is important that traffic is not disrupted or that network performance is not adversely affected while re-routes are underway. This is done by establishing a new tunnel and transferring traffic onto it before tearing down the old tunnel.
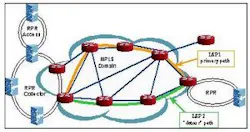
As shown in Figure 2, RPRs can be interconnected by an intelligent core that provides for a reliable method of rerouting under changing conditions that can include
- A more optimal route becomes available.
- Failure of a network resource.
- Return to the original path upon resource recovery.
- When services are carried over multiple hierarchies of RPR rings (e.g., access and collector rings as shown in the figure), or in a mesh of rings. In this case, RPR can repair the fault at the ring level and simultaneously provide the protection detection capabilities to an MPLS control plane to enable it to perform and-to-end LSP recovery if needed.
- When services are carried over an IP-based network between RPR-based networks.
Conclusion
As packet networks grow to encompass services that require a high level of reliability, end-user expectations (often based on experience with the voice network) will demand resilient solutions like those provided by RPR. These techniques let us have our cake and eat it too, by allowing significantly improved bandwidth utilization, simplified maintenance, and packet-optimized architectures while still maintaining the resilience end-users demand for high-end services.
In addition to being members of the RPR Alliance, John Hawkins works for Nortel Networks; Gady Rosenfeld works for Corrigent Systems, and Kanaiya Vasani works for Lantern Communications. The RPR Alliance was established to promote standards-based RPR technology and to encourage the utilization and implementation of RPR as a key networking technology for connectivity of various computing, data and telecommunications devices.